
 United States
United States
 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Alpk3 (NM_054085) Mouse Tagged ORF Clone
CAT#: MR218500
- TrueORF®
Alpk3 (Myc-DDK-tagged) - Mouse alpha-kinase 3 (Alpk3)
ORF Plasmid: tGFP
"NM_054085" in other vectors (2)
Need custom modification / cloning service?
Get a free quote
CNY 11,296.00
Product images

CNY 300.00
Specifications
| Product Data | |
| Type | Mouse Tagged ORF Clone |
| Tag | Myc-DDK |
| Synonyms | AW319487; D330016D04; MAK; Midori; mKIAA1330 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>MR218500 representing NM_054085
Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGGGTCGCGGAGGGCCGCGGGCCGGGGCTGGGGCCTGGGTGGTCGAGCAGGAGCTGGTGGAGATAGCG AGGACGACGGGCCGGTGTGGACGCCCGGCCCAGCCAGTCGCAGCTACTTGCTTAGCGTGCGGCCAGAGGC TAGCTTATCAAGCAACCGGTTGTCTCACCCCAGCTCTGGAAGGAGCACCTTCTGCTCCATCATTGCTCAG CTCACAGAGGAGACCCAGCCACTGTTCGAGACCACACTCAAGTCCCGTGCCGTGTCCGAAGACAGTGACG TCAGGTTCACCTGCATTGTCACAGGATACCCAGAGCCAGAGGTGACCTGGTACAAGGATGACATAGAACT GGACCGTTACTGTGGCTTGCCAAAATACGAGATCACTCATCAAGGCAACCGTCACACCCTGCAGCTGTAC AGGTGTCAGGAAGAAGATGCTGCCATCTACCAAGCCTCTGCCCGGAACACCAAGGGCATCGTGTCCTGCT CAGGGGTCCTAGAGGTGGGCACTATGACGGAGTACAAGATTCACCAGCGCTGGTTCGCCAAGTTGAAGCG CAAGGCTGCAGCCAAGATGAGGGAGATTGAGCAGAGCTGGAAGCATGGAAAAGAGGCTTCAGGGGAGGCT GACACGCTTCTTCGCAAGATCAGCCCCGACCGCTTCCAAAGAAAGCGCCGACTGAGTGGAGTCGAAGAGG CTGTCCTCTCCACGCCAGTCAGGGAAATGGAGGAAGGCTCCTCAGCGGCTTGGCAGGAAGGAGAGACTGA GTCTGCTCAGCACCCGGGGTTGGGTTTGATCAACAGTTTTGCTCCTGGAGAGGCGCCCACCAATGGGGAG CCTGCTCCAGAGAACGGGGAAGACGAAGAGCGTGGCTTGCTGACATACATCTGCGAGGTCATGGAACTGG GGCCTCAGAACAGCCCTCCAAAGGAGTCTGGGGCTAAGAAGAAAAGGAAGGATGAGGAATCTAAACCAGG AGAGCAGAAGCTGGAGTTAGAAAAGGCAGAAGGGAGCCAGTGCTCTTCAGAAAACGTCGTCCCCAGTACA GACAAACCCAACTCCAGTAGAAGGGAGAAGTCCACGGATACACAGCCAGCTCAGACCCAGCCCAGAGGCC GGGTAGCACGGGGGCCTGGGATAGAAAGCACCAGGAAGACAGCCTCTGTCCTGGGCATTCAAGACAAGGT CCAGGATGTCCCCGCCCCCGCCCCTGCCCCGGTCCCCGCCCCAGCCCTGGCCCCGGCCCCTGTCCCAGTC CCTGCACCCACCCCTGTTCCAAGCCGCAGCTCAGAGCAGGTGTATTTCTCCCTGAAGGACATGTTCATGG AGACCACCCGGGCAGGCAGGTCCCAGGAAGAGGAAAAACCTCCACCTCCAAGTACCAGGGTAGCTGGAGA AAGTCCCCCAGGAAAGACACCAGTCAAGTCTAGACTGGAGAAGGTACCGATGGTCTCCAGCCAGCCCACA TCTTCCATGGTTCCCCCGCCCATTAAGCCTTTGAACAGGAAGAGATTTGCCCCTCCTAAATCCAAAGTGG AGTCAACTACTACCTCTCTCTCAAGTCAGACTTCAGAATCTATGGCCCAGAGCTTAGGGAAGGCTCTACC TTCAGCCTCTACCCAGGTCCCAACACCCCCTGCTCGACGGAGACACGGCACCCGAGATAGCCCCTTGCAA GGACAAACGAGCCACAAGACTCCAGGAGAGGCTCTGGAGTCCCCAGCAACCGTGGCTCCCACCAAGTCTG CCAACAGCAGCTCCGATACCGTCTCTGTTGATCACGACAGCTCTGGAAATCAAGGGGCCACGGAGCCCAT GGATACAGAAACTCAGGAAGATGGAAGGACACTTGTGGATGGGAGAACTGGAAGCAGGAAGAAAACACAC ACAGATGGAAAGCTGCAAGTGGATGGGAGGACTCAGGGAGACGGAGCACAAGACAGAGCACACGCTTCGC CAAGGACACAGGCAGGTGAGAAGGCACCGACGGACGTTGTGACACAAGGAAGTGAGAGGCCACAGTCAGA CAGGAGTTCATGGAAGAATTTGGTGACACAGAGAAGAGTGGATATGCAGGTAGGACAGATGCAGGCAGGT GAGAGGTGGCAGCAAGACCCTGGAGACGCAAGGATACAGGAGGAAGAAAAAGAGACACAGTCAGCAGCAG GCAGCATTCCTGTAGCTTTCGAAACCCAATCAGAGCAGTTGTCCATGGCCAGCCTCAGCTCACTTCCTGG AGCTCTCAAAGGCTCACCATCAGGATGCCCTAGAGAGTCCCAGGCTATAGAATGTTTTGAGAAGAGCACA GAGGCACCCTGTGTCCAAGAAAGATCTGACTTGATGCTGCGGTCTGAAGAGGCAGCCTTCAGAAGCCATG AGGATGGGCTGCTAGGCCCCCCATCAGGGAACCGTACCTACCCAACACAGTTGCCTCCCGAGGGGCACTC AGAGCATTTGGGAGGACAAACACATCAAAGGTCAGAGCAAGAGGACAGCCTGTCTCAGTGCCCCAAGAAG GAGCAGCCCCAGGAACCGCTTCATGTGGGTCTCTCTGGTGGGCATTCAACTGGCTTGAGTCAGGAGGTGC CTGCCATGCCTTCTCTTCCTGGGACGGGCCTAACCAGTAGTCTGCAGGAGGAGCTACCAGGCACCGCAGC TTCTCTGCACACAAACACAGATGTCCCCCTCCCCTCCAGGGACCAGGACTTTCCGAGTTCTGCTCCCACT CTGCAATTGGGGCCAGGGTCCCCCACTCAGAGTCACCCACCAGAAGCCATGGCTACTAGCAGTGAGGGAG CCTGTGCCAAGGAGCCAAATGTGGACGGGAGGTCCTCAGGTACCCGGAGCTGTGACCCTGGCCTTATAGA TTCCCTGAAGAACTACTTGCTTCTGCTGCTGAAGCTATCCAGTCCAGAGACAAGTGAAGCCAGGGCCGAG TCCCAGGAAGTGGCAGACACCGGGGGCTTAACCTCCTCCTCTACTCTGGTCCCCACCATGGAGGTGGCTG GGCTGAGTCCCAGGACGTCGAGGCGAATCCTGGAACGCGTGGAGAACAATCACTTAGTGCAGAGTGCACA GACCCTGTTGCTGAGCCCCTGCACCTCCCGCCGCCTTACTGGCCTTCTGGACCGTGAGGTACAGGCTGGC CAGCAGGCTCTGGCTGCTGCCCAGTGCTCTCGGGGCCCGTGCCCCACCCCCCTCACCATCCCTGCCATTG TGGTGGGTGAGGAAGGATCTGCGGGAGAGGATTCCGAGGAGAGGACTTCGCAGGAAAGTGACAAGAAGGG ACTGCTAGGGGAAGTGGAGGGGCACACAGTGGAAAGCAGAACCCAGGAGCCCTGCCAAGAAGAAGCAATG CCAGGGGAGGCTTTGACGGGTCTCCCTGCAGCTACACCCGAGGAACTGGCTCTGGGGGCCCGGAGGAAGA GGTTCCTCCCTAAGGTCAGAGCAGGGTCAGATGGAGAGGCAAACAAGGCTGAAGAAAGGGAGAGCCCCAC GGTTTCCCCCCGGGGACCCAGGAAGGGCCTGACACCTGGGTCACCAGGGACTCCAGGGCGGGAGAGACGG TCCCCTACCCAGGCCCGAAAAGCCAGCATGTTAGAGGTGCCTGGCGCAGAAGAAGAGCCTGCAACTGGAG ACTTGGTCTCCAGATCCAAAGACAGTGGCCTGGACTCAGAGCCTGCGGTGGATGAAGGCAAGCAGGAAGC TCTGGCCAAGCAAAGGAAAGCTAAGGACCTGCTAAAAGCCCCACAGGTGATCCGGAAAATTCGGGTGGAA CAGTTTCCAGATTCTTCTGGTAGTCTGAAGCTTTGGTGCCAGTTTTTCAACATTGTTAGTGACTCAGTCT TGACATGGGCGAAGGATCAGCACCCAGTGGGCGAAGTGAACAGGAGTGCAGGGGACGAGGGGCCAGCGGC TTTGGCCATCGTGCAGGCGTCTCCCACGGACTGTGGTGTGTATCGCTGTACCATCCAAAACGAGCATGGC TCAGCGTCCACTGACTTCTGCCTCAGCCCCGAGGTATTGTCCGGCTTCATCTCCAGAGAGGAAGGTGAAG TTGGAGAAGAGATTGAGATGACCCCCATGGTGTTTGCTAAGGGTCTGGCTGACTCTGGCTGCTGGGGGGA CAAGCTCTTTGGGCGATTGGTGAGCGAGGAACTTCGAGGGGGTGGACATGGCCTTCAGAAGGCGTCCCGG GCCAAGGTCATCTATGGGCTGGAACCCATCTTCGAATCTGGCCGCACGTGCATCATCAAAGTATCCAGCC TGCTTGTGTTCGGACCCAGCAGTGAGACCTCTCTTCTGGGCAGAAACTATGACGTCACTATCCAGGGATG CAAGATCCAGAACATGAGTCGAGAGTACTGCAAAATCTTTGCAGCTGAAGCCCGGGCGGCCTCTGGCTTC GGAGAGGTGCCCGAGATCATCCCACTCTACTTGATCTACCGGCCTGCAAACAATATACCATATGCAACCC TGGAGGAAGATCTGGGCAAGCCCCTGCAGACTTACTGTTCCAGGCAGTGGGGCTGTGCTGGGGCCCCCGC AGCAGCCAGCAGCTCCGAGGCCTTGCAGAAATGCCAAACCTTCCAGCACTGGCTGTATCAGTGGACAAAC GGCAGCTTTCTTGTCACAGATCTGACAGGAGCTGACTGGAAGATGACTGATGTACAGATTGCTACCAAAC TTCGAGGATACCAAGGCCTCAAGGAGAGCTGTTTTCCTGCCCTGCTGGACCAGTTTGCCTCTTCCCACCA GTGTAACACCTACTGTGACATGCTGGGGCTGAAGCCCCTCAAAGGCCCTGAGGCTGCCCACCCTCAAGCC AAGGCCAAAGGCTCCAAAAGTCCATCTGCTGGCAGAAAAGGCTCACAGCTGAGTCCTCAACCCCAGAAGA AAGGCCTTCCCAGTCCCCAGGGCTCCAGGAAGAGCGCTCCAAGCTCCAGGGCTACACTTCAGGCCTCCCA GGCAGCCACTGTTCAGTTACTGGGACAGCCTCCTGTCCAAGATGGGAGCTCTAAGGCCCAGAGCATGCGG AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCC TGGATTACAAGGATGACGACGATAAGGTTTAA >MR218500 representing NM_054085
Red=Cloning site Green=Tags(s) MGSRRAAGRGWGLGGRAGAGGDSEDDGPVWTPGPASRSYLLSVRPEASLSSNRLSHPSSGRSTFCSIIAQ LTEETQPLFETTLKSRAVSEDSDVRFTCIVTGYPEPEVTWYKDDIELDRYCGLPKYEITHQGNRHTLQLY RCQEEDAAIYQASARNTKGIVSCSGVLEVGTMTEYKIHQRWFAKLKRKAAAKMREIEQSWKHGKEASGEA DTLLRKISPDRFQRKRRLSGVEEAVLSTPVREMEEGSSAAWQEGETESAQHPGLGLINSFAPGEAPTNGE PAPENGEDEERGLLTYICEVMELGPQNSPPKESGAKKKRKDEESKPGEQKLELEKAEGSQCSSENVVPST DKPNSSRREKSTDTQPAQTQPRGRVARGPGIESTRKTASVLGIQDKVQDVPAPAPAPVPAPALAPAPVPV PAPTPVPSRSSEQVYFSLKDMFMETTRAGRSQEEEKPPPPSTRVAGESPPGKTPVKSRLEKVPMVSSQPT SSMVPPPIKPLNRKRFAPPKSKVESTTTSLSSQTSESMAQSLGKALPSASTQVPTPPARRRHGTRDSPLQ GQTSHKTPGEALESPATVAPTKSANSSSDTVSVDHDSSGNQGATEPMDTETQEDGRTLVDGRTGSRKKTH TDGKLQVDGRTQGDGAQDRAHASPRTQAGEKAPTDVVTQGSERPQSDRSSWKNLVTQRRVDMQVGQMQAG ERWQQDPGDARIQEEEKETQSAAGSIPVAFETQSEQLSMASLSSLPGALKGSPSGCPRESQAIECFEKST EAPCVQERSDLMLRSEEAAFRSHEDGLLGPPSGNRTYPTQLPPEGHSEHLGGQTHQRSEQEDSLSQCPKK EQPQEPLHVGLSGGHSTGLSQEVPAMPSLPGTGLTSSLQEELPGTAASLHTNTDVPLPSRDQDFPSSAPT LQLGPGSPTQSHPPEAMATSSEGACAKEPNVDGRSSGTRSCDPGLIDSLKNYLLLLLKLSSPETSEARAE SQEVADTGGLTSSSTLVPTMEVAGLSPRTSRRILERVENNHLVQSAQTLLLSPCTSRRLTGLLDREVQAG QQALAAAQCSRGPCPTPLTIPAIVVGEEGSAGEDSEERTSQESDKKGLLGEVEGHTVESRTQEPCQEEAM PGEALTGLPAATPEELALGARRKRFLPKVRAGSDGEANKAEERESPTVSPRGPRKGLTPGSPGTPGRERR SPTQARKASMLEVPGAEEEPATGDLVSRSKDSGLDSEPAVDEGKQEALAKQRKAKDLLKAPQVIRKIRVE QFPDSSGSLKLWCQFFNIVSDSVLTWAKDQHPVGEVNRSAGDEGPAALAIVQASPTDCGVYRCTIQNEHG SASTDFCLSPEVLSGFISREEGEVGEEIEMTPMVFAKGLADSGCWGDKLFGRLVSEELRGGGHGLQKASR AKVIYGLEPIFESGRTCIIKVSSLLVFGPSSETSLLGRNYDVTIQGCKIQNMSREYCKIFAAEARAASGF GEVPEIIPLYLIYRPANNIPYATLEEDLGKPLQTYCSRQWGCAGAPAAASSSEALQKCQTFQHWLYQWTN GSFLVTDLTGADWKMTDVQIATKLRGYQGLKESCFPALLDQFASSHQCNTYCDMLGLKPLKGPEAAHPQA KAKGSKSPSAGRKGSQLSPQPQKKGLPSPQGSRKSAPSSRATLQASQAATVQLLGQPPVQDGSSKAQSMR SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
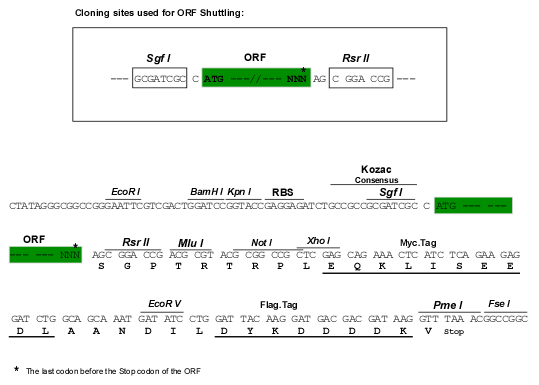
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_054085 |
| ORF Size | 5040 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_054085.2, NP_473426.2 |
| RefSeq Size | 6369 bp |
| RefSeq ORF | 5043 bp |
| Locus ID | 116904 |
| MW | 180.6 kDa |
Documents
| Product Manuals |
| FAQs |
| SDS |

{kind=link}