
 United States
United States
 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
Isocitrate dehydrogenase (IDH1) Human Gene Knockout Kit (CRISPR)
CAT#: KN210582
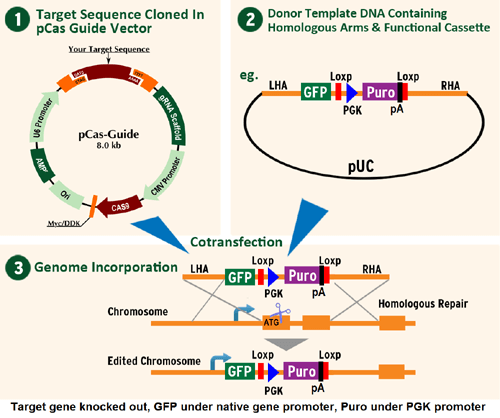
IDH1 - human gene knockout kit via CRISPR, HDR mediated
HDR-mediated knockout kit validation
CNY 12,260.00
Product images
CNY 3,710.00
CNY 1,999.00
CNY 2,700.00
CNY 5,488.00
Specifications
| Product Data | |
| Format | 2 gRNA vectors, 1 GFP-puro donor, 1 scramble control |
| Donor DNA | GFP-puro |
| Symbol | Isocitrate dehydrogenase |
| Locus ID | 3417 |
| Kit Components |
KN210582G1, Isocitrate dehydrogenase gRNA vector 1 in pCas-Guide CRISPR vector, Target Sequence: ATGTCCAAAAAAATCAGTGG KN210582G2, Isocitrate dehydrogenase gRNA vector 2 in pCas-Guide CRISPR vector, Target Sequence: GGTTCTGTGGTAGAGATGCA KN210582-D, donor DNA containing left and right homologous arms and GFP-puro functional cassette. pUC vector backbone in gray; Left arm sequence in blue; GFP-puro in green; Right arm in violet AAGGCGAGTT ACATGATCCC CCATGTTGTG CAAAAAAGCG GTTAGCTCCT TCGGTCCTCC GATCGTTGTC AGAAGTAAGT TGGCCGCAGT GTTATCACTC ATGGTTATGG CAGCACTGCA TAATTCTCTT ACTGTCATGC CATCCGTAAG ATGCTTTTCT GTGACTGGTG AGTACTCAAC CAAGTCATTC TGAGAATAGT GTATGCGGCG ACCGAGTTGC TCTTGCCCGG CGTCAATACG GGATAATACC GCGCCACATA GCAGAACTTT AAAAGTGCTC ATCATTGGAA AACGTTCTTC GGGGCGAAAA CTCTCAAGGA TCTTACCGCT GTTGAGATCC AGTTCGATGT AACCCACTCG TGCACCCAAC TGATCTTCAG CATCTTTTAC TTTCACCAGC GTTTCTGGGT GAGCAAAAAC AGGAAGGCAA AATGCCGCAA AAAAGGGAAT AAGGGCGACA CGGAAATGTT GAATACTCAT ACTCTTCCTT TTTCAATATT ATTGAAGCAT TTATCAGGGT TATTGTCTCA TGAGCGGATA CATATTTGAA TGTATTTAGA AAAATAAACA AATAGGGGTT CCGCGCACAT TTCCCCGAAA AGTGCCACCT GACGTCTAAG AAACCATTAT TATCATGACA TTAACCTATA AAAATAGGCG TATCACGAGG CCCTTTCGGG TCGCGCGTTT CGGTGATGAC GGTGAAAACC TCTGACACAT GCAGCTCCCG TTGACGGTCA CAGCTTGTCT GTAAGCGGAT GCCGGGAGCA GACAAGCCCG TCAGGGCGCG TCAGCGGGTG TTGGCGGGTG TCGGGGCTGG CTTAACTATG CGGCATCAGA GCAGATTGTA CTGAGAGTGC ACCATAAAAT TGTAAACGTT AATATTTTGT TAAAATTCGC GTTAAATTTT TGTTAAATCA GCTCATTTTT TAACCAATAG GCCGAAATCG GCAAAATCCC TTATAAATCA AAAGAATAGC CCGAGATAGG GTTGAGTGTT GTTCCAGTTT GGAACAAGAG TCCACTATTA AAGAACGTGG ACTCCAACGT CAAAGGGCGA AAAACCGTCT ATCAGGGCGA TGGCCCACTA CGTGAACCAT CACCCAAATC AAGTTTTTTG GGGTCGAGGT GCCGTAAAGC ACTAAATCGG AACCCTAAAG GGAGCCCCCG ATTTAGAGCT TGACGGGGAA AGCCGGCGAA CGTGGCGAGA AAGGAAGGGA AGAAAGCGAA AGGAGCGGGC GCTAGGGCGC TGGCAAGTGT AGCGGTCACG CTGCGCGTAA CCACCACACC CGCCGCGCTT AATGCGCCGC TACAGGGCGC GTACTATGGT TGCTTTGACG TATGCGGTGT GAAATACCGC ACAGATGCGT AAGGAGAAAA TACCGCATCA GGCGCCATTC GCCATTCAGG CTGCGCAACT GTTGGGAAGG GCGATCGGTG CGGGCCTCTT CGCTATTACG CCAGCTGGCG AAAGGGGGAT GTGCTGCAAG GCGATTAAGT TGGGTAACGC CAGGGTTTTC CCAGTCACGA CGTTGTAAAA CGACGGCCAG TGAATTGGAG GCTACAGTCA GTGGAGAGGA CTTTCACAGG CTGTCGCCGT GCTCATTTGA TAACTGCCCG TTATTCATGC GACACTGAAT ATGGGTCACA GGAACCAGCT GAATCTCCTC ATGGCTAGTT ATTTTTATTA AATAACAAAA ACAGCCTCTT AAAGGAGGAG AAATGCTAGC ACTCACCATT CTGGACATCT TGAGAGCCCA GTAAAATGAT GAGTTGGACT GAAGTGTTCA ATAAACATGA GATTGTGGAA ATAATCTCAT TTCTTAAGAC AAACCAGTAG TTGAGAATAA TGATTGCATT ATGAAGGGCA CGTTATAGGG TCAGGCTCTG CCACGCTCTA GCTAGGTGGC CTTGGGAAAG CTCTTTTTTT TTTAACAAAG TAAAATGGGG AAATGATGGC CATTTTTTTG GATTGTTATG AGGGCTAGCT CAGAAACCGC GTGTGAAACA TAACACAATA CTTTGTTCAG AGAAGATACT CAATTCTAAT GGTAAATAGA ATTGCTGTTA CTAGCTTTTT ATTCAACTAC ACATAAATTG AATTGCATGA ATTGTTCTTT TAGTAGTCAC TACGTTGTTT ATATAAACAC TACGTTGTTT ATATATTTCA CTTTATAATG AAATAAATGA CAAGGCATGT ATTTTTTTTT TCTTTTTAGG TTTATTGAAG TCAAAACTAG CATGGAGAGC GACGAGAGCG GCCTGCCCGC CATGGAGATC GAGTGCCGCA TCACCGGCAC CCTGAACGGC GTGGAGTTCG AGCTGGTGGG CGGCGGAGAG GGCACCCCCG AGCAGGGCCG CATGACCAAC AAGATGAAGA GCACCAAAGG CGCCCTGACC TTCAGCCCCT ACCTGCTGAG CCACGTGATG GGCTACGGCT TCTACCACTT CGGCACCTAC CCCAGCGGCT ACGAGAACCC CTTCCTGCAC GCCATCAACA ACGGCGGCTA CACCAACACC CGCATCGAGA AGTACGAGGA CGGCGGCGTG CTGCACGTGA GCTTCAGCTA CCGCTACGAG GCCGGCCGCG TGATCGGCGA CTTCAAGGTG ATGGGCACCG GCTTCCCCGA GGACAGCGTG ATCTTCACCG ACAAGATCAT CCGCAGCAAC GCCACCGTGG AGCACCTGCA CCCCATGGGC GATAACGATC TGGATGGCAG CTTCACCCGC ACCTTCAGCC TGCGCGACGG CGGCTACTAC AGCTCCGTGG TGGACAGCCA CATGCACTTC AAGAGCGCCA TCCACCCCAG CATCCTGCAG AACGGGGGCC CCATGTTCGC CTTCCGCCGC GTGGAGGAGG ATCACAGCAA CACCGAGCTG GGCATCGTGG AGTACCAGCA CGCCTTCAAG ACCCCGGATG CAGATGCCGG TGAAGAAAGA GTTTAAGAAT TCCGATCATA TTCAATAACC CTTAATATAA CTTCGTATAA TGTATGCTAT ACGAAGTTAT TAGGTCTGAA GAGGAGTTTA CGTCCAGCCA AGCTTAGGAT CTCGACCTCG AAATTCTACC GGGTAGGGGA GGCGCTTTTC CCAAGGCAGT CTGGAGCATG CGCTTTAGCA GCCCCGCTGG GCACTTGGCG CTACACAAGT GGCCTCTGGC CTCGCACACA TTCCACATCC ACCGGTAGGC GCCAACCGAC TCCGTTCTTT GGTGGCCCCT TCGCGCCACC TTCTACTCCT CCCCTAGTCA GGAAGTTCCC CCCCGCCCCG CAGCTCGCGT CGTGCAGGAC GTGACAAATG GAAGTAGCAC GTCTCACTAG TCTCGTGCAG ATGGACAGCA CCGCTGAGCA ATGGAAGCGG GTAGGCCTTT GGGGCAGCGG CCAATAGCAG CTTTGCTCCT TCGCTTTCTG GGCTCAGAGG CTGGGAAGGG GTGGGTCCGG GGGCGGGCTC AGGGGCGGGC TCAGGGGCGG GGCGGGCGCC CGAAGGTCCT CCGGAGGCCC GGCATTCTGC ACGCTTCAAA AGCGCACGTC TGCCGCGCTG TTCTCCTCTT CCTCATCTCC GGGCCTTTCG ACCTGCATCC ATCTAGATCT CGAGCAGCTG AAGCTTACCA TGACCGAGTA CAAGCCCACG GTGCGCCTCG CCACCCGCGA CGACGTCCCC AGGGCCGTAC GCACCCTCGC CGCCGCGTTC GCCGACTACC CCGCCACGCG CCACACCGTC GATCCGGACC GCCACATCGA GCGGGTCACC GAGCTGCAAG AACTCTTCCT CACGCGCGTC GGGCTCGACA TCGGCAAGGT GTGGGTCGCG GACGACGGCG CCGCGGTGGC GGTCTGGACC ACGCCGGAGA GCGTCGAAGC GGGGGCGGTG TTCGCCGAGA TCGGCCCGCG CATGGCCGAG TTGAGCGGTT CCCGGCTGGC CGCGCAGCAA CAGATGGAAG GCCTCCTGGC GCCGCACCGG CCCAAGGAGC CCGCGTGGTT CCTGGCCACC GTCGGCGTCT CGCCCGACCA CCAGGGCAAG GGTCTGGGCA GCGCCGTCGT GCTCCCCGGA GTGGAGGCGG CCGAGCGCGC CGGGGTGCCC GCCTTCCTGG AGACCTCCGC GCCCCACAAC CTCCCCTTCT ACGAGCGGCT CGGCTTCACC GTCACCGCCG ACGTCGAGGT GCCCGAAGGA CCGCGCACCT GGTGCATGAC CCGCAAGCCC GGTGCCTGAC GCCCGCCCCA CGACCCGCAG CGCCCGACCG AAAGGAGCGC ACGACCCCAT GCATCGATGA TATCAGATCC CCGGGATGCA GAAATTGATG ATCTATTAAA CAATAAAGAT GTCCACTAAA ATGGAAGTTT TTCCTGTCAT ACTTTGTTAA GAAGGGTGAG AACAGAGTAC CTACATTTTG AATGGAAGGA TTGGAGCTAC GGGGGTGGGG GTGGGGTGGG ATTAGATAAA TGCCTGCTCT TTACTGAAGG CTCTTTACTA TTGCTTTATG ATAATGTTTC ATAGTTGGAT ATCATAATTT AAACAAGCAA AACCAAATTA AGGGCCAGCT CATTCCTCCC ACTCATGATC TATAGATCTA TAGATCTCTC GTGGGATCAT TGTTTTTCTC TTGATTCCCA CTTTGTGGTT CTAAGTACTG TGGTTTCCAA ATGTGTCAGT TTCATAGCCT GAAGAACGAG ATCAGCAGCC TCTGTTCCAC ATACACTTCA TTCTCAGTAT TGTTTTGCCA AGTTCTAATT CCATCAGAAG CTGGTCGAGA TCCGGAACCC TTAATATAAC TTCGTATAAT GTATGCTATA CGAAGTTATT AGGTCCCTCG AAGAGGTTCA CTAGGCGCGC CACGAATCAT TTGGGAATTG ATTAAAGAGA AACTCATTTT TCCCTACGTG GAATTGGATC TACATAGGTA AATGAGTTAC CCCTCCGTGT AGCAAACTCA GAAAGGATAA TCTGGCTGGG CATGGTGGTG CACACGTGAA GTCCCAGCTA CTTAGGAGGC AGAGGCAGGA GGATCCCTCA AGACCAGGAA TTCAAGTCCA GCCTGGGCAA CAGAGTGAGA CCCCATCACT TTAAAAAAAA AAGGAAAAAA AAGGGAAGGA GAAACAGGAA AAAAAAAAAG AATATAATCT GAATTATTTT GAGGTGAAGT TAGCTTTTTT TATATAGATA TAGCTGTGTT TTGTGAATAA AGTTTGTTTT AAGCCTAAAT ATATTCAGAT GAATCTTCTA ATTTTAACAT ACTGCTAGAA AAACTGGATT TATCATCTAA AAGTCAAGAA TTATAAGGGA AAGAATGATT TTCAGATTCT TCTAACCTTC TGTTTCCTGT GAAGGTTTTA TTTGTAATAA AACAGTGGCT AAGAATAGTA CAATGTATTG AGAAAAGGGA AATAAGAGAG GATGTAAGAA ACAGTAAACT AAATGCAGTT AACACAATTT TTCACTCTCG CCGGTTGGAC TTTAGATCAG AAGGGATCTT GCTGCCGCCC GAAAGAGGAA GGGCTGGAAG AGGAAGGAGC TTGGCGTAAT CATGGTCATA GCTGTTTCCT GTGTGAAATT GTTATCCGCT CACAATTCCA CACAACATAC GAGCCGGAAG CATAAAGTGT AAAGCCTGGG GTGCCTAATG AGTGAGCTAA CTCACATTAA TTGCGTTGCG CTCACTGCCC GCTTTCCAGT CGGGAAACCT GTCGTGCCAG CTGCATTAAT GAATCGGCCA ACGCGCGGGG AGAGGCGGTT TGCGTATTGG GCGCTCTTCC GCTTCCTCGC TCACTGACTC GCTGCGCTCG GTCGTTCGGC TGCGGCGAGC GGTATCAGCT CACTCAAAGG CGGTAATACG GTTATCCACA GAATCAGGGG ATAACGCAGG AAAGAACATG TGAGCAAAAG GCCAGCAAAA GGCCAGGAAC CGTAAAAAGG CCGCGTTGCT GGCGTTTTTC CATAGGCTCC GCCCCCCTGA CGAGCATCAC AAAAATCGAC GCTCAAGTCA GAGGTGGCGA AACCCGACAG GACTATAAAG ATACCAGGCG TTTCCCCCTG GAAGCTCCCT CGTGCGCTCT CCTGTTCCGA CCCTGCCGCT TACCGGATAC CTGTCCGCCT TTCTCCCTTC GGGAAGCGTG GCGCTTTCTC ATAGCTCACG CTGTAGGTAT CTCAGTTCGG TGTAGGTCGT TCGCTCCAAG CTGGGCTGTG TGCACGAACC CCCCGTTCAG CCCGACCGCT GCGCCTTATC CGGTAACTAT CGTCTTGAGT CCAACCCGGT AAGACACGAC TTATCGCCAC TGGCAGCAGC CACTGGTAAC AGGATTAGCA GAGCGAGGTA TGTAGGCGGT GCTACAGAGT TCTTGAAGTG GTGGCCTAAC TACGGCTACA CTAGAAGAAC AGTATTTGGT ATCTGCGCTC TGCTGAAGCC AGTTACCTTC GGAAAAAGAG TTGGTAGCTC TTGATCCGGC AAACAAACCA CCGCTGGTAG CGGTGGTTTT TTTGTTTGCA AGCAGCAGAT TACGCGCAGA AAAAAAGGAT CTCAAGAAGA TCCTTTGATC TTTTCTACGG GGTCTGACGC TCAGTGGAAC GAAAACTCAC GTTAAGGGAT TTTGGTCATG AGATTATCAA AAAGGATCTT CACCTAGATC CTTTTAAATT AAAAATGAAG TTTTAAATCA ATCTAAAGTA TATATGAGTA AACTTGGTCT GACAGTTACC AATGCTTAAT CAGTGAGGCA CCTATCTCAG CGATCTGTCT ATTTCGTTCA TCCATAGTTG CCTGACTCCC CGTCGTGTAG ATAACTACGA TACGGGAGGG CTTACCATCT GGCCCCAGTG CTGCAATGAT ACCGCGAGAA CCACGCTCAC CGGCTCCAGA TTTATCAGCA ATAAACCAGC CAGCCGGAAG GGCCGAGCGC AGAAGTGGTC CTGCAACTTT ATCCGCCTCC ATCCAGTCTA TTAATTGTTG CCGGGAAGCT AGAGTAAGTA GTTCGCCAGT TAATAGTTTG CGCAACGTTG TTGCCATTGC TACAGGCATC GTGGTGTCAC GCTCGTCGTT TGGTATGGCT TCATTCAGCT CCGGTTCCCA ACGATCGE100003, scramble sequence in pCas-Guide vector |
| Disclaimer | These products are manufactured and supplied by OriGene under license from ERS. The kit is designed based on the best knowledge of CRISPR technology. The system has been functionally validated for knocking-in the cassette downstream the native promoter. The efficiency of the knock-out varies due to the nature of the biology and the complexity of the experimental process. |
| Reference Data | |
| RefSeq | NM_001282386, NM_001282387, NM_005896, N21575 |
| Synonyms | HEL-216; HEL-S-26; IDCD; IDH; IDP; IDPC; PICD |
| Summary | Isocitrate dehydrogenases catalyze the oxidative decarboxylation of isocitrate to 2-oxoglutarate. These enzymes belong to two distinct subclasses, one of which utilizes NAD(+) as the electron acceptor and the other NADP(+). Five isocitrate dehydrogenases have been reported: three NAD(+)-dependent isocitrate dehydrogenases, which localize to the mitochondrial matrix, and two NADP(+)-dependent isocitrate dehydrogenases, one of which is mitochondrial and the other predominantly cytosolic. Each NADP(+)-dependent isozyme is a homodimer. The protein encoded by this gene is the NADP(+)-dependent isocitrate dehydrogenase found in the cytoplasm and peroxisomes. It contains the PTS-1 peroxisomal targeting signal sequence. The presence of this enzyme in peroxisomes suggests roles in the regeneration of NADPH for intraperoxisomal reductions, such as the conversion of 2, 4-dienoyl-CoAs to 3-enoyl-CoAs, as well as in peroxisomal reactions that consume 2-oxoglutarate, namely the alpha-hydroxylation of phytanic acid. The cytoplasmic enzyme serves a significant role in cytoplasmic NADPH production. Alternatively spliced transcript variants encoding the same protein have been found for this gene. [provided by RefSeq, Sep 2013] |
Documents
| Product Manuals |
| FAQs |
Resources
| 基因表达相关资源 |
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| KN210582BN | IDH1 - human gene knockout kit via CRISPR, HDR mediated |
CNY 12,260.00 |
|
| KN210582LP | IDH1 - human gene knockout kit via CRISPR, HDR mediated |
CNY 12,260.00 |
|
| KN210582RB | IDH1 - human gene knockout kit via CRISPR, HDR mediated |
CNY 12,260.00 |
|
| KN410582 | IDH1 - KN2.0, Human gene knockout kit via CRISPR, non-homology mediated. |
CNY 8,680.00 |
|
| GA102310 | IDH1 CRISPRa kit - CRISPR gene activation of human isocitrate dehydrogenase (NADP(+)) 1, cytosolic |
CNY 12,255.00 |
其它Isocitrate dehydrogenase产品
